- About
- Solutions
- Essentials
- Utilities
- Publications
- Product Delivery
- Support

The HPE Shadowbase QMGR is an optional process that sits between the Collector and a Consumer that safely (persistently) stores the replication data for that Consumer on disk. The data is either stored on the sending side, or the receiving side.

Each Consumer is fed by at most one QMGR. Each Consumer that a Collector feeds can independently, optionally, have its own QMGR.
As shown in Figure 1, it decouples the need for the network or target environment to be available and accessible for the Collector to continue processing source data. If configured on the source system, it provides network and Consumer independence. A slow (or inaccessible) Consumer’s data is queued for processing, allowing the Collector to continue reading the audit trail and transmitting to all Consumers.
When this catastrophic event occurs, the target system has the data queued, even if the Consumer is behind in its processing or cannot access the target database. The QMGR reduces the RPO for an asynchronous HPE Shadowbase data replication environment, and sets the RPO to zero (0, zero data loss, or ZDL) for a synchronous HPE Shadowbase data replication environment. In other words, when the QMGR is located on the target side, using a QMGR will either reduce the potential for data loss when a failure occurs (asynchronous Shadowbase replication), or eliminate the potential for data loss when a failure occurs (synchronous Shadowbase ZDL replication).
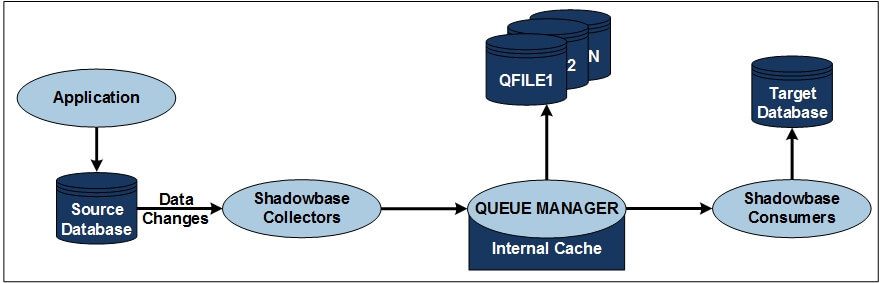
Figure 1 — HPE Shadowbase Queue Manager (QMGR) Flow Chart
Figure 1 shows the process and data flows in a Shadowbase replication system that has a Queue Manager (QMGR). An application posts its changes to a source database, the data changes are read by the Shadowbase Collector(s), which then prepares the data for transport. The Collector(s) forward the changes to the QMGR. The QMGR stores the data in the in-memory cache, and buffers and writes the data to disk-based queue files in large blocks, which makes the entire system more efficient by reducing the number of write operations to disk. The QMGR’s in-memory cache passes the data to the Shadowbase Consumer(s), and the Shadowbase Consumer(s) then applies the changes to the target database. Once this process is complete, the QMGR’s disk file information, previously written in large blocks, is marked as delivered. During this process, if the Consumer(s) is not running or unable to take the data from the in-memory cache, the QMGR will later read the data back from the disk queue file and send it to the Consumer(s) when it is ready to apply the changes into the target database.
Adding a QMGR into a Collector/Consumer replication thread does not typically increase the latency time from when the event occurred on the source to when the event is replayed on the target (assuming the Consumer can keep up with the data generation rate). This is because the QMGR maintains an in-memory cache and forwards data to the target Consumer as soon as it is received without waiting for it to be written to disk. Typically, the Consumer is the slowest component of this replication sequence.
Data is first stored in the in-memory cache, as well as buffered and written (in streaming append mode) to the queue disk files in large blocks, reducing the number of write operations to the disk. Data is only read from disk when it is not available in the QMGR’s in-memory cache. When required, data is read sequentially in large blocks, again minimizing the number of read operations against a queue file disk.
All of the major parameters affecting performance are configurable, allowing the QMGR to be tuned for a specific transaction profile.
All I/Os are performed using “no-waited” I/O and are non-blocking, improving throughput and reducing replication latency.
If a replication failure and restart occurs, the data stored in the queue is used to recover, and the source system continues sending from the last acknowledged block it sent before the failure. Hence, on a restart, the Collector needs to re-read and re-send less source data.
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print