- About
- Solutions
- Essentials
- Utilities
- Publications
- Product Delivery
- Support
 Last week HPE published a new case study, Cartu Bank ensures continuous availability of payment services for Georgian businesses. Cartu Bank understands the need for continuous availability with more than 60% of all e-commerce transactions in the Eastern European country of Georgia going through its payment switch. Read how HPE NonStop servers run mission-critical BASE24 payment engines to keep the Georgian economy running 24×7. Giorgi Ioramashvili, head of Cartu Bank’s IT department, remarks, “It was important to our solution to have replication software like Shadowbase integrated with the NonStop servers. We looked at Oracle GoldenGate, which also could replicate BASE24, but because Shadowbase operates natively within the NonStop operating environment, it was more stable and easier to work with. Plus, Shadowbase was 40% to 50% less expensive than Oracle GoldenGate.”
Last week HPE published a new case study, Cartu Bank ensures continuous availability of payment services for Georgian businesses. Cartu Bank understands the need for continuous availability with more than 60% of all e-commerce transactions in the Eastern European country of Georgia going through its payment switch. Read how HPE NonStop servers run mission-critical BASE24 payment engines to keep the Georgian economy running 24×7. Giorgi Ioramashvili, head of Cartu Bank’s IT department, remarks, “It was important to our solution to have replication software like Shadowbase integrated with the NonStop servers. We looked at Oracle GoldenGate, which also could replicate BASE24, but because Shadowbase operates natively within the NonStop operating environment, it was more stable and easier to work with. Plus, Shadowbase was 40% to 50% less expensive than Oracle GoldenGate.”
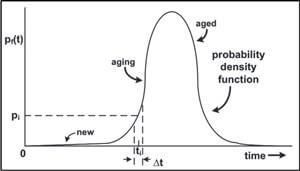 Gravic recently published a two-part series in The Connection on Improving Availability via Staggered Systems. The first part covers MTTF – Mean Time To Failure while the second part focuses on Mitigating Redundant Failures via System Staggering. The reliability of a redundant system is optimized by minimizing the probability that both systems will fail simultaneously. If they both have the same failure probability distribution, then when one system is most likely to fail, so is the other system. Previous methods for calculating estimated availability from any point in time are flawed because they are based on memoryless random variables. The calculation of the average time to the next failure is always the same, regardless of how long a system has been in service. By staggering the system starting times so that their probability distributions are not aligned, the time that the two systems are most likely to fail are different. When one system is most likely to fail, the probability that the other system will fail is significantly reduced. Therefore, the probability of a dual system failure is reduced. Redundant system reliability can be greatly enhanced by staggering the starting times of the two systems. This strategy applies both to hardware failures and to software failures.
Gravic recently published a two-part series in The Connection on Improving Availability via Staggered Systems. The first part covers MTTF – Mean Time To Failure while the second part focuses on Mitigating Redundant Failures via System Staggering. The reliability of a redundant system is optimized by minimizing the probability that both systems will fail simultaneously. If they both have the same failure probability distribution, then when one system is most likely to fail, so is the other system. Previous methods for calculating estimated availability from any point in time are flawed because they are based on memoryless random variables. The calculation of the average time to the next failure is always the same, regardless of how long a system has been in service. By staggering the system starting times so that their probability distributions are not aligned, the time that the two systems are most likely to fail are different. When one system is most likely to fail, the probability that the other system will fail is significantly reduced. Therefore, the probability of a dual system failure is reduced. Redundant system reliability can be greatly enhanced by staggering the starting times of the two systems. This strategy applies both to hardware failures and to software failures.
 Gravic published an article in the March/April issue of The Connection called Improving Reliability via Redundant Processing. One of the three pillars of mission-critical systems is data reliability – a significant concern in data centers worldwide. Data reliability can be ensured via a special configuration that compares the operation of one sub-system to another sub-system running the same applications. Verification may be accomplished by comparing results generated by the two sub-systems at specific synchronization points. If the results agree, the sub-systems are operating properly, if not, corrective action can be taken. This article suggests that the comparison of transaction-processing output via a Transaction Indicia Matching (TIM) module is a significant improvement over the use of a Logical Synchronization Unit (LSU), which represent a single point of failure in a system. A version of a TIM can be implemented with HPE Shadowbase synchronous data replication.
Gravic published an article in the March/April issue of The Connection called Improving Reliability via Redundant Processing. One of the three pillars of mission-critical systems is data reliability – a significant concern in data centers worldwide. Data reliability can be ensured via a special configuration that compares the operation of one sub-system to another sub-system running the same applications. Verification may be accomplished by comparing results generated by the two sub-systems at specific synchronization points. If the results agree, the sub-systems are operating properly, if not, corrective action can be taken. This article suggests that the comparison of transaction-processing output via a Transaction Indicia Matching (TIM) module is a significant improvement over the use of a Logical Synchronization Unit (LSU), which represent a single point of failure in a system. A version of a TIM can be implemented with HPE Shadowbase synchronous data replication.

Gravic published a case study in February, called A Large Financial Institution Migrates Datacenters with No Downtime Using HPE Shadowbase ZDM. A major financial company offers person-to-person money transfers, money orders, and business payments. The company implemented an active/active system with two NonStop systems located 1,000 miles apart, and the databases were synchronized with a legacy bi-directional data replication solution. When the company decided to move its systems to other cities, upgrading them in the process, it could not tolerate an application outage during the move, so it relied on HPE Shadowbase Zero Downtime Migration (ZDM) software to avoid application downtime and provide full business continuity protection while the move took place. Its customers were able to make money transfers and use all applications as the servers and services were relocated. The company also relied on HPE Shadowbase ZDM to replace its legacy data replication software product and position itself for continuous availability into the future.
To discuss your data replication, data integration, and application integration needs, please email us at [email protected], or call us at +1.610.647.6250.
 Copy link to clipboard
Copy link to clipboard Email link
Email link Print
Print